Chat with SOLAS Documentation
AI-powered RAG system for maritime regulations with hybrid search and intelligent reranking
Version: 1.0.0 | Status: Active Development | Updated: October 20, 2025
What is Chat with SOLAS?
Chat with SOLAS is an AI-powered Retrieval-Augmented Generation (RAG) system designed for maritime safety professionals to quickly find accurate information in complex regulatory documents.
Key Capabilities
- Hybrid Search: Combines semantic search (OpenAI embeddings) with BM25 keyword matching for optimal retrieval
- Cross-Encoder Reranking: Local sentence-transformers model scores query-document pairs for maximum relevance
- Interactive PDF Viewer: Click any citation to jump directly to the source page in the PDF
- Hierarchical Citations: Complete navigation path (Convention → Chapter → Regulation → Paragraph) with page numbers
- Category Filtering: Separate tabs for Conventions (SOLAS, MARPOL, etc.), SMS, and Emergency documents
Core Technology Stack
| Layer | Technology | Purpose |
|---|---|---|
| Backend Framework | FastAPI | REST API and async document processing |
| Frontend Framework | React 18 + TypeScript | Interactive UI with PDF viewer |
| Vector Database | Qdrant | Semantic search with OpenAI embeddings |
| Keyword Search | rank-bm25 | Traditional keyword-based retrieval |
| Reranking | sentence-transformers | Local cross-encoder (ms-marco-MiniLM-L-6-v2) |
| LLM | OpenAI GPT-4o | Answer generation and synthesis |
| PDF Processing | PyPDF2 + PyMuPDF | Text extraction and page rendering |
| Database | SQLite | Document metadata and query logs |
Supported Document Categories
- Conventions: SOLAS, MARPOL, MLC, STCW
- SMS: Safety Management System procedures
- Emergency: Emergency response plans (SMPEP, PUN, etc.)
System Architecture
High-Level Architecture
┌─────────────────────────────────────────────────────────────┐
│ Frontend (React 18) │
│ ┌──────────────┐ ┌──────────────┐ ┌──────────────┐ │
│ │ Documents │ │ PDF Viewer │ │ Chat │ │
│ │ List │ │ │ │ Interface │ │
│ └──────────────┘ └──────────────┘ └──────────────┘ │
└──────────────────────────┬──────────────────────────────────┘
│ HTTP/REST API
┌──────────────────────────┴──────────────────────────────────┐
│ Backend (FastAPI + Python) │
│ ┌─────────────────────┐ ┌─────────────────────┐ │
│ │ Document Indexing │ │ RAG Query Engine │ │
│ │ • PDF Extraction │ │ • Hybrid Search │ │
│ │ • Smart Chunking │ │ • RRF Fusion │ │
│ │ • Hierarchy Parse │ │ • Reranking │ │
│ └─────────────────────┘ └─────────────────────┘ │
│ │
│ ┌──────────────────────────────────────────────────────┐ │
│ │ External Services │ │
│ │ • Qdrant (Vector DB) • OpenAI (LLM + Embeddings) │ │
│ │ • sentence-transformers (Local Reranking) │ │
│ └──────────────────────────────────────────────────────┘ │
└──────────────────────────────────────────────────────────────┘4-Stage RAG Pipeline
The pipeline starts with 30 candidates each from semantic and keyword search, fuses them to 20, then reranks to final top 10 for maximum accuracy.
Stage 1: Semantic Search (Qdrant)
├─ OpenAI text-embedding-3-small (1536 dimensions)
├─ Cosine similarity search
└─ Returns: 30 candidates
Stage 2: Keyword Search (BM25)
├─ rank-bm25 implementation
├─ TF-IDF scoring with term weighting
└─ Returns: 30 candidates
Stage 3: Reciprocal Rank Fusion (RRF)
├─ Combines both result sets
├─ Deduplicates and scores: 1 / (k + rank)
└─ Returns: 20 candidates for reranking
Stage 4: Cross-Encoder Reranking
├─ sentence-transformers: ms-marco-MiniLM-L-6-v2
├─ Scores each query-document pair directly
├─ Filters by MIN_RERANK_SCORE = -2.0
└─ Returns: Final top 10 chunksData Flow
- Document Upload: User uploads PDF via frontend
- Background Indexing: FastAPI BackgroundTasks trigger processing
- Text Extraction: PyPDF2 extracts text from PDF
- Smart Chunking: ~2400 chars per chunk, 100-word overlap
- Hierarchy Detection: Regex patterns extract Convention, Chapter, Regulation, Paragraph
- Vector Embedding: OpenAI embeddings for each chunk
- Storage: Qdrant (vectors) + SQLite (metadata) + BM25 corpus
- Query: User asks question → Hybrid search → Rerank → LLM synthesis
- Response: Answer with citations, page numbers, rerank scores
Installation
Prerequisites
- Python 3.10+
- Node.js 18+
- Docker (for Qdrant)
- OpenAI API key
Backend Setup
# Clone repository
git clone https://github.com/SL-Mar/Chat_with_SOLAS.git
cd Chat_with_SOLAS
# Create virtual environment
python3 -m venv venv
source venv/bin/activate # or `venv\Scripts\activate` on Windows
# Install dependencies
pip install -r backend/requirements.txt
# Create .env file
cat > backend/.env << EOF
OPENAI_API_KEY=your_openai_api_key_here
QDRANT_HOST=localhost
QDRANT_PORT=6333
QDRANT_COLLECTION=maritime_rag
APP_HOST=0.0.0.0
APP_PORT=8001
UPLOAD_DIR=uploads
MAX_UPLOAD_SIZE_MB=100
EOF
# Start Qdrant with Docker
docker run -d -p 6333:6333 -v $(pwd)/qdrant_storage:/qdrant/storage qdrant/qdrant
# Run backend
cd backend
uvicorn app.main:app --host 0.0.0.0 --port 8001 --reloadFrontend Setup
# Install dependencies
cd frontend
npm install
# Create .env file
echo "VITE_API_URL=http://localhost:8001" > .env
# Run frontend
npm run dev
# Open browser
# http://localhost:5173Download the sentence-transformers reranking model (~80MB) on first query. This is a one-time operation and runs locally (CPU-only PyTorch).
Quick Start Guide
1. Upload a Maritime Document
- Navigate to the appropriate tab (Conventions/SMS/Emergency)
- Click the "+ Upload" button in the Documents panel
- Select a PDF file (max 100MB)
- Document is automatically indexed in the background
- Status changes: uploaded → indexing → indexed
2. Query the Documents
- Ensure you're in the correct tab for your document type
- Type your question in the chat input (e.g., "What are the fire drill requirements?")
- Press Enter or click "Send"
- Answer appears with citations and rerank scores
- Click "X Source Citations" to expand and view chunk details
3. View Source in PDF
- Click any citation in the chat panel
- PDF viewer automatically opens to the referenced page
- Document is loaded in the center panel
- Navigate with page controls or scroll
Example Query Flow
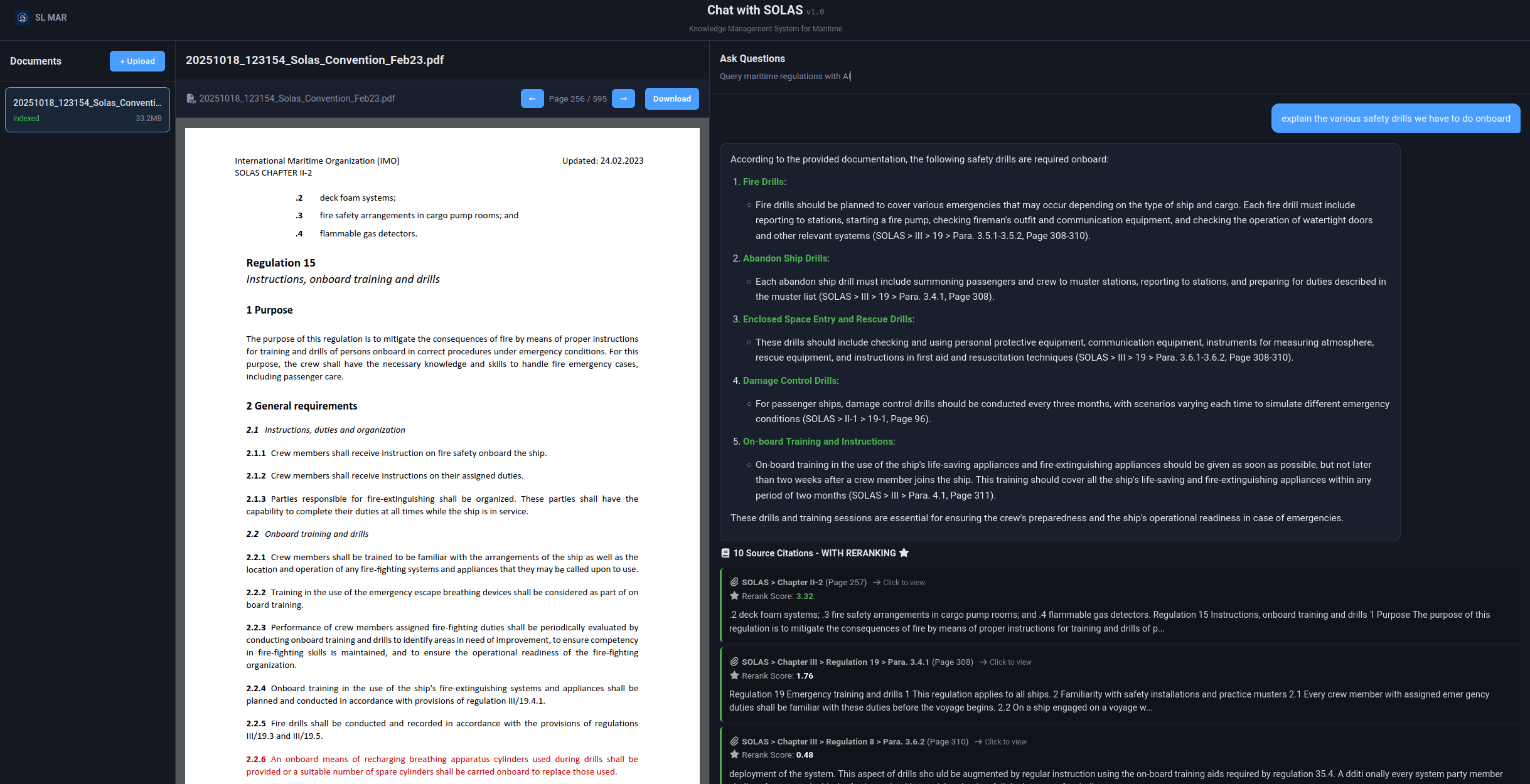
User Query: "Explain the various safety drills we have to do onboard"
System Processing:
1. Semantic search: 30 chunks from Qdrant
2. BM25 search: 30 chunks from rank-bm25
3. RRF fusion: 20 combined candidates
4. Cross-encoder reranking: Top 10 chunks
Retrieved Chunks:
• SOLAS > Chapter II-2 > Regulation 15 (Page 257, Rerank: 3.32)
• SOLAS > Chapter III > Regulation 19 (Page 308, Rerank: 1.76)
• SOLAS > Chapter III (Page 310, Rerank: 0.48)
Generated Answer:
"According to SOLAS regulations, vessels must conduct the following safety drills:
**Fire Drills** (Chapter II-2, Regulation 15):
- Every crew member must participate in at least one fire drill monthly
- Drills must include use of fire extinguishers and hoses
- Emergency fire pump must be operated
- Crew must report to their fire stations with protective equipment
**Abandon Ship Drills** (Chapter III, Regulation 19):
- Every crew member must participate in at least one abandon ship drill monthly
- Must include donning of lifejackets
- Reporting to muster stations
- Launching of at least one lifeboat
**Additional Drills:**
- Enclosed space entry and rescue drills
- Damage control drills
- On-board training must occur within 2 weeks of joining the vessel"
User Action:
Click citation "SOLAS > Chapter II-2 > Regulation 15 (Page 257)" to view exact text in PDFHybrid Search
Why Hybrid Search?
Traditional semantic search (embeddings) excels at understanding meaning but can miss exact keyword matches. BM25 keyword search is great for precise terms but struggles with synonyms and paraphrasing. Hybrid search combines both approaches for optimal recall and precision.
Semantic Search (Qdrant)
- Embedding Model: text-embedding-3-small (OpenAI)
- Dimensions: 1536
- Similarity Metric: Cosine similarity
- Candidates: 30 chunks
- Strengths: Understanding synonyms, paraphrasing, conceptual queries
- Weaknesses: May miss exact keyword matches
Keyword Search (BM25)
- Implementation: rank-bm25 (Python library)
- Algorithm: TF-IDF with term frequency saturation and length normalization
- Candidates: 30 chunks
- Strengths: Exact keyword matching, regulatory code references
- Weaknesses: No understanding of synonyms or meaning
Reciprocal Rank Fusion (RRF)
RRF merges both result sets using a rank-based scoring formula:
RRF_score(chunk) = sum(1 / (k + rank_in_list))
Where:
- k = 60 (constant for smoothing)
- rank_in_list = position in semantic or BM25 results
- sum = across both lists
Example:
Chunk appears at rank 5 in semantic, rank 10 in BM25:
RRF_score = 1/(60+5) + 1/(60+10) = 0.0154 + 0.0143 = 0.0297Category Filtering
Both semantic and BM25 searches are filtered by document_type metadata:
- Conventions Tab: document_type IN (SOLAS, MARPOL, MLC, STCW)
- SMS Tab: document_type = SMS
- Emergency Tab: document_type = Emergency
- Use natural language questions for semantic search
- Include specific regulatory codes for exact matches (e.g., "Regulation 15")
- Query in the correct tab for your document category
- Rephrase queries if initial results are not satisfactory
Cross-Encoder Reranking
Why Reranking?
Traditional bi-encoder models (used in semantic search) encode queries and documents separately, then compute similarity. Cross-encoders encode query and document together, capturing deeper semantic relationships for superior relevance scoring.
Bi-Encoder vs Cross-Encoder
| Aspect | Bi-Encoder | Cross-Encoder |
|---|---|---|
| Speed | Fast (pre-computed embeddings) | Slower (pair scoring at query time) |
| Accuracy | Good | Excellent |
| Use Case | Initial retrieval (1000s of docs) | Reranking (10s of candidates) |
| Encoding | Separate (query || document) | Joint (query + document together) |
Implementation Details
- Model: cross-encoder/ms-marco-MiniLM-L-6-v2
- Size: ~80MB
- Inference: CPU-only PyTorch (local, no API calls)
- Input: 20 candidates from RRF fusion
- Output: Relevance scores for each query-document pair
- Filtering: MIN_RERANK_SCORE = -2.0 (removes very low-quality matches)
- Final Selection: Top 10 chunks by rerank score
Reranking Process
from sentence_transformers import CrossEncoder
# Initialize model (one-time download ~80MB)
model = CrossEncoder('cross-encoder/ms-marco-MiniLM-L-6-v2')
# Prepare query-document pairs
pairs = [(query, chunk['text']) for chunk in candidates]
# Score all pairs
scores = model.predict(pairs)
# Filter and sort
filtered = [(chunk, score) for chunk, score in zip(candidates, scores)
if score >= MIN_RERANK_SCORE]
top_10 = sorted(filtered, key=lambda x: x[1], reverse=True)[:10]Score Interpretation
- > 3.0: Excellent relevance (highly confident match)
- 1.0 - 3.0: Good relevance (strong match)
- 0.0 - 1.0: Moderate relevance (potential match)
- -2.0 - 0.0: Low relevance (weak match, still included)
- < -2.0: Filtered out (no relevance)
Reranking adds ~200-500ms to query time but dramatically improves answer quality. The model runs locally, so there are no additional API costs beyond OpenAI embeddings and LLM.
Interactive PDF Viewer
Features
- Page-by-Page Rendering: PyMuPDF renders each page as PNG at 300 DPI
- Citation Navigation: Click any citation to jump to the exact page
- Page Controls: Previous/Next buttons, page input, total pages display
- Zoom: Fit-to-width, fit-to-height, or custom zoom levels
- Full-Screen Mode: Expand PDF to full browser window
Backend API
GET /api/documents/{document_id}/page/{page_num}
Query Parameters:
- search_text (optional): Highlight specific text on the page
Response:
{
"image": "data:image/png;base64,...",
"width": 2480,
"height": 3508,
"page_num": 257,
"total_pages": 854,
"text_positions": [
{"x": 15.2, "y": 42.1, "width": 8.3, "height": 1.2}
]
}Frontend Implementation
- Library: react-pdf for PDF rendering
- State Management: React hooks for page navigation
- Citation Linking: onClick handler updates selectedDocument and targetPage
- Loading States: Skeleton screens while rendering pages
Usage Example
// User clicks citation in chat
<div onClick={() => {
if (citationDoc) {
setSelectedDocument(citationDoc);
setTargetPage(citation.page);
}
}}>
SOLAS > Chapter II-2 > Regulation 15 (Page 257)
</div>
// PDFViewer component receives props
<PDFViewer
documentId={selectedDocument.id}
filename={selectedDocument.original_filename}
initialPage={targetPage} // Jump to page 257
/>Smart Chunking with Hierarchy Detection
Why Smart Chunking?
Maritime regulations have strict hierarchical structure (Convention → Annex → Chapter → Regulation → Paragraph). Preserving this structure in chunk metadata enables precise citations and better retrieval accuracy.
Chunking Strategy
- Chunk Size: ~2400 characters (optimal for embedding models)
- Overlap: 100 words between chunks (preserves context at boundaries)
- Splitting: Sentence-based splitting to avoid mid-sentence cuts
- Page Tracking: Each chunk stores its original page number
Hierarchy Detection Patterns
Convention Patterns:
- r'SOLAS'
- r'MARPOL'
- r'STCW'
- r'MLC'
Annex Patterns:
- r'Annex\s+([IVX]+)' → "Annex I", "Annex VI"
Chapter Patterns:
- r'Chapter\s+([IVX]+-?\d*)' → "Chapter II-2", "Chapter III"
- r'CHAPTER\s+([IVX]+-?\d*)'
Regulation Patterns:
- r'Regulation\s+(\d+\.?\d*)' → "Regulation 15", "Regulation 19.2"
- r'REGULATION\s+(\d+\.?\d*)'
Paragraph Patterns:
- r'(?:^|\n)(\d+\.\d+(?:\.\d+)?)\s' → "2.1", "3.4.1"
- r'Para(?:graph)?\.\s*(\d+\.\d+(?:\.\d+)?)'Metadata Structure
Each chunk stored in Qdrant includes:
{
"text": "Chunk text content...",
"page": 257,
"source": "SOLAS_2020.pdf",
"document_id": 1,
"document_type": "SOLAS",
"convention": "SOLAS",
"annex": "Annex I",
"chapter": "Chapter II-2",
"regulation": "Regulation 15",
"paragraph": "2.1",
"hierarchy_path": "SOLAS > Annex I > Chapter II-2 > Regulation 15 > Para. 2.1"
}Citation Generation
def build_citation(chunk):
parts = []
if chunk.get('convention'):
parts.append(chunk['convention'])
if chunk.get('annex'):
parts.append(f"Annex {chunk['annex']}")
if chunk.get('chapter'):
parts.append(chunk['chapter'])
if chunk.get('regulation'):
parts.append(chunk['regulation'])
if chunk.get('paragraph'):
parts.append(f"Para. {chunk['paragraph']}")
return ' > '.join(parts) if parts else chunk.get('section', 'Unknown')Category Filtering
Three-Tab Architecture
Documents are organized into three categories for focused searching:
1. Conventions Tab
- Document Types: SOLAS, MARPOL, MLC, STCW
- Use Case: International maritime safety and environmental regulations
- Example Queries: "Fire drill requirements", "Lifeboat capacity calculation"
2. SMS Tab
- Document Type: SMS
- Use Case: Company-specific Safety Management System procedures
- Example Queries: "Permit to work procedure", "Risk assessment form"
3. Emergency Tab
- Document Type: Emergency
- Use Case: Emergency response plans and checklists
- Example Queries: "Oil spill response procedure", "Fire emergency plan"
Implementation
Frontend (React)
const [activePage, setActivePage] = useState<PageType>('conventions');
// Separate message history per tab
const [messagesByTab, setMessagesByTab] = useState<Record<PageType, ChatMessage[]>>({
conventions: [],
sms: [],
emergency: []
});
// Filter documents by active tab
const filteredDocuments = documents.filter(doc => {
if (activePage === 'conventions') {
return ['SOLAS', 'MARPOL', 'MLC', 'STCW'].includes(doc.document_type);
} else if (activePage === 'sms') {
return doc.document_type === 'SMS';
} else {
return doc.document_type === 'Emergency';
}
});Backend (FastAPI)
class QueryRequest(BaseModel):
query: str
top_k: Optional[int] = None
category: Optional[str] = None # 'conventions', 'sms', 'emergency'
@app.post("/api/query")
def query_documents(request: QueryRequest):
# Map category to document_types
if request.category == 'conventions':
doc_types = ['SOLAS', 'MARPOL', 'MLC', 'STCW']
elif request.category == 'sms':
doc_types = ['SMS']
elif request.category == 'emergency':
doc_types = ['Emergency']
else:
doc_types = None # No filtering
# Apply filtering in Qdrant and BM25
chunks = rag_engine.retrieve_relevant_chunks(
request.query,
request.top_k,
doc_types
)Always ensure you're querying in the correct tab. SOLAS content won't appear in Emergency tab searches, even if the question is emergency-related.
API Reference
RESTful API endpoints for document management and querying.
Base URL
http://localhost:8001Documents API
Upload Document
POST /api/documents/upload
Content-Type: multipart/form-data
Body:
- file: PDF file (max 100MB)
- document_type: "SOLAS" | "MARPOL" | "MLC" | "STCW" | "SMS" | "Emergency"
Response:
{
"id": 1,
"filename": "20251020_120000_SOLAS_2020.pdf",
"original_filename": "SOLAS_2020.pdf",
"file_size": 5242880,
"document_type": "SOLAS",
"upload_date": "2025-10-20T12:00:00",
"indexed_date": null,
"status": "uploaded",
"total_chunks": 0,
"error_message": null
}Index Document
POST /api/documents/{document_id}/index
Response:
{
"message": "Indexing started",
"document_id": 1
}List Documents
GET /api/documents
Response:
[
{
"id": 1,
"filename": "20251020_120000_SOLAS_2020.pdf",
"original_filename": "SOLAS_2020.pdf",
"file_size": 5242880,
"document_type": "SOLAS",
"upload_date": "2025-10-20T12:00:00",
"indexed_date": "2025-10-20T12:05:30",
"status": "indexed",
"total_chunks": 854,
"error_message": null
}
]Get Document
GET /api/documents/{document_id}
Response: Same as List Documents (single object)Delete Document
DELETE /api/documents/{document_id}
Response:
{
"message": "Document deleted",
"document_id": 1
}Preview PDF
GET /api/documents/{document_id}/preview
Response: PDF file (application/pdf)Get PDF Page
GET /api/documents/{document_id}/page/{page_num}?search_text={optional}
Response:
{
"image": "data:image/png;base64,...",
"width": 2480,
"height": 3508,
"page_num": 257,
"total_pages": 854,
"text_positions": [...]
}Query API
Query Documents
POST /api/query
Content-Type: application/json
Body:
{
"query": "What are the fire drill requirements?",
"top_k": 10,
"category": "conventions"
}
Response:
{
"answer": "According to SOLAS Chapter II-2, Regulation 15...",
"query": "What are the fire drill requirements?",
"retrieved_chunks": [
{
"text": "Fire drill procedures...",
"page": 257,
"convention": "SOLAS",
"annex": null,
"chapter": "Chapter II-2",
"regulation": "Regulation 15",
"paragraph": "2.1",
"hierarchy_path": "SOLAS > Chapter II-2 > Regulation 15 > Para. 2.1",
"section": "Fire Safety",
"source": "SOLAS_2020.pdf",
"score": 0.87,
"rerank_score": 3.32,
"original_score": 0.87
}
],
"total_chunks_retrieved": 10,
"response_time_ms": 2340
}List Queries
GET /api/queries?limit=50
Response:
[
{
"id": 1,
"query_text": "What are the fire drill requirements?",
"answer_text": "According to SOLAS...",
"retrieved_chunks": 10,
"response_time_ms": 2340,
"created_at": "2025-10-20T12:10:00"
}
]Health API
Health Check
GET /health
Response:
{
"status": "healthy",
"qdrant_connected": true,
"openai_configured": true
}Root Endpoint
GET /
Response:
{
"message": "Maritime RAG API",
"version": "1.0.0"
}RAG Pipeline Deep Dive
Complete Query Flow
- User Input: "What are the fire drill requirements?"
- Category Detection: Check active tab (conventions/sms/emergency)
- Semantic Search:
- Embed query with OpenAI text-embedding-3-small
- Query Qdrant with category filter
- Retrieve 30 candidates by cosine similarity
- BM25 Search:
- Tokenize query
- Filter BM25 corpus by category
- Retrieve 30 candidates by BM25 score
- RRF Fusion:
- Merge both result sets
- Deduplicate chunks
- Score with RRF formula
- Return top 20 candidates
- Cross-Encoder Reranking:
- Score each (query, chunk) pair
- Filter by MIN_RERANK_SCORE = -2.0
- Sort by rerank score
- Return top 10 chunks
- LLM Synthesis:
- Build context from top 10 chunks (~21,600 chars)
- Send to GPT-4o with system prompt
- Generate answer (max 3000 tokens)
- Extract citations from context
- Response Formatting:
- Markdown formatting for answer
- Attach chunk metadata (page, hierarchy, scores)
- Log query to database
- Return JSON response
System Prompt
You are a maritime regulations expert assistant.
Your role is to provide accurate, well-structured answers
based on the provided document chunks.
Guidelines:
1. Answer the question using ONLY information from the context
2. Include specific regulation references (Chapter, Regulation, Paragraph)
3. Use markdown formatting for clarity
4. If information is not in the context, say so clearly
5. Structure answers with headings and bullet points when appropriate
6. Be concise but complete
Context:
{chunk1_text}
Source: {chunk1_source} (Page {chunk1_page})
{chunk2_text}
Source: {chunk2_source} (Page {chunk2_page})
...
Question: {user_query}
Answer:Hierarchy Detection Implementation
Detection Logic
def detect_hierarchy(text: str, current_page: int) -> dict:
"""
Extract hierarchical metadata from maritime document text
Returns:
dict with keys: convention, annex, chapter, regulation, paragraph
"""
hierarchy = {
'convention': None,
'annex': None,
'chapter': None,
'regulation': None,
'paragraph': None,
'page': current_page
}
# Convention detection
for convention in ['SOLAS', 'MARPOL', 'STCW', 'MLC']:
if convention in text:
hierarchy['convention'] = convention
break
# Annex detection
annex_match = re.search(r'Annex\s+([IVX]+)', text)
if annex_match:
hierarchy['annex'] = annex_match.group(1)
# Chapter detection
chapter_match = re.search(r'Chapter\s+([IVX]+-?\d*)', text, re.IGNORECASE)
if chapter_match:
hierarchy['chapter'] = f"Chapter {chapter_match.group(1)}"
# Regulation detection
reg_match = re.search(r'Regulation\s+(\d+\.?\d*)', text, re.IGNORECASE)
if reg_match:
hierarchy['regulation'] = f"Regulation {reg_match.group(1)}"
# Paragraph detection
para_match = re.search(r'(?:^|\n)(\d+\.\d+(?:\.\d+)?)\s', text)
if para_match:
hierarchy['paragraph'] = para_match.group(1)
return hierarchyEdge Cases Handled
- Multiple conventions in one chunk: First match wins
- Missing hierarchy levels: Null values for missing parts
- Case variations: Regex patterns with re.IGNORECASE
- Formatting variations: Multiple patterns per hierarchy level
Database Schema
SQLite Tables
documents
CREATE TABLE documents (
id INTEGER PRIMARY KEY AUTOINCREMENT,
filename VARCHAR NOT NULL,
original_filename VARCHAR NOT NULL,
file_path VARCHAR NOT NULL,
file_size INTEGER NOT NULL,
document_type VARCHAR,
upload_date DATETIME DEFAULT CURRENT_TIMESTAMP,
indexed_date DATETIME,
status VARCHAR DEFAULT 'uploaded',
total_chunks INTEGER DEFAULT 0,
error_message TEXT
);queries
CREATE TABLE queries (
id INTEGER PRIMARY KEY AUTOINCREMENT,
query_text TEXT NOT NULL,
answer_text TEXT,
retrieved_chunks INTEGER,
response_time_ms INTEGER,
created_at DATETIME DEFAULT CURRENT_TIMESTAMP
);Qdrant Collection
Collection: maritime_rag
Vectors:
- Size: 1536 (OpenAI text-embedding-3-small)
- Distance: Cosine
Payload Schema:
{
"text": str, # Chunk text
"page": int, # Original page number
"source": str, # Filename
"document_id": int, # Foreign key to documents table
"document_type": str, # Category for filtering
"convention": str, # SOLAS, MARPOL, etc.
"annex": str, # Annex identifier
"chapter": str, # Chapter number
"regulation": str, # Regulation number
"paragraph": str, # Paragraph number
"hierarchy_path": str, # Full path for citations
"section": str # Fallback section name
}Configuration
Environment Variables
# OpenAI API
OPENAI_API_KEY=your_api_key_here
# Qdrant Vector DB
QDRANT_HOST=localhost
QDRANT_PORT=6333
QDRANT_COLLECTION=maritime_rag
# Application
APP_HOST=0.0.0.0
APP_PORT=8001
# File Upload
UPLOAD_DIR=uploads
MAX_UPLOAD_SIZE_MB=100
# RAG Configuration (optional, defaults in code)
RETRIEVAL_TOP_K=10
EMBEDDING_MODEL=text-embedding-3-small
CHAT_MODEL=gpt-4o
LLM_MAX_TOKENS=3000
LLM_TEMPERATURE=0.3
MIN_RERANK_SCORE=-2.0Tunable Parameters
| Parameter | Default | Purpose |
|---|---|---|
| RETRIEVAL_TOP_K | 10 | Final number of chunks sent to LLM |
| SEMANTIC_CANDIDATES | 30 | Chunks from Qdrant semantic search |
| BM25_CANDIDATES | 30 | Chunks from BM25 keyword search |
| RRF_CANDIDATES | 20 | Chunks after RRF fusion (before reranking) |
| MIN_RERANK_SCORE | -2.0 | Minimum cross-encoder score to include chunk |
| CHUNK_SIZE | 2400 | Characters per chunk |
| CHUNK_OVERLAP | 100 | Words overlap between chunks |
| LLM_MAX_TOKENS | 3000 | Maximum tokens for LLM answer |
| LLM_TEMPERATURE | 0.3 | LLM creativity (0=factual, 1=creative) |
GitHub Repository
Repository: https://github.com/SL-Mar/Chat_with_SOLAS
Repository Structure
Chat_with_SOLAS/
├── backend/
│ ├── app/
│ │ ├── main.py # FastAPI application
│ │ ├── rag_engine.py # RAG logic (retrieval + reranking)
│ │ ├── bm25_search.py # BM25 implementation
│ │ ├── database.py # SQLAlchemy models
│ │ ├── config.py # Settings and env vars
│ │ └── utils.py # Telegram notifications
│ ├── requirements.txt # Python dependencies
│ └── .env.example # Environment variables template
│
├── frontend/
│ ├── src/
│ │ ├── App.tsx # Main React component
│ │ ├── components/
│ │ │ └── PDFViewer.tsx # PDF rendering component
│ │ ├── api/
│ │ │ └── client.ts # API client
│ │ └── index.css # Global styles
│ ├── package.json # Node dependencies
│ └── .env.example # Frontend env vars
│
├── uploads/ # Uploaded PDFs (gitignored)
├── qdrant_storage/ # Qdrant data (gitignored)
└── README.md # Project overviewThis is an open-source project. Contributions, bug reports, and feature requests are welcome via GitHub Issues and Pull Requests.
Use Cases
1. Safety Officers
- Challenge: Quick answers during inspections and audits
- Solution: Search SOLAS/MARPOL regulations in seconds with exact citations
- Example: "What are the requirements for lifeboat drills?"
2. Training Departments
- Challenge: Creating accurate training materials from multiple sources
- Solution: Query regulations, get synthesized answers with source references
- Example: "Compare fire drill requirements across different vessel types"
3. Ship Operators
- Challenge: Verifying regulatory requirements for equipment and procedures
- Solution: Instant access to regulation text with PDF preview
- Example: "What is the minimum capacity for inflatable liferafts?"
4. Compliance Teams
- Challenge: Researching regulatory changes and fleet-wide compliance
- Solution: Compare multiple conventions and track regulatory updates
- Example: "Has MARPOL Annex VI changed since 2020?"
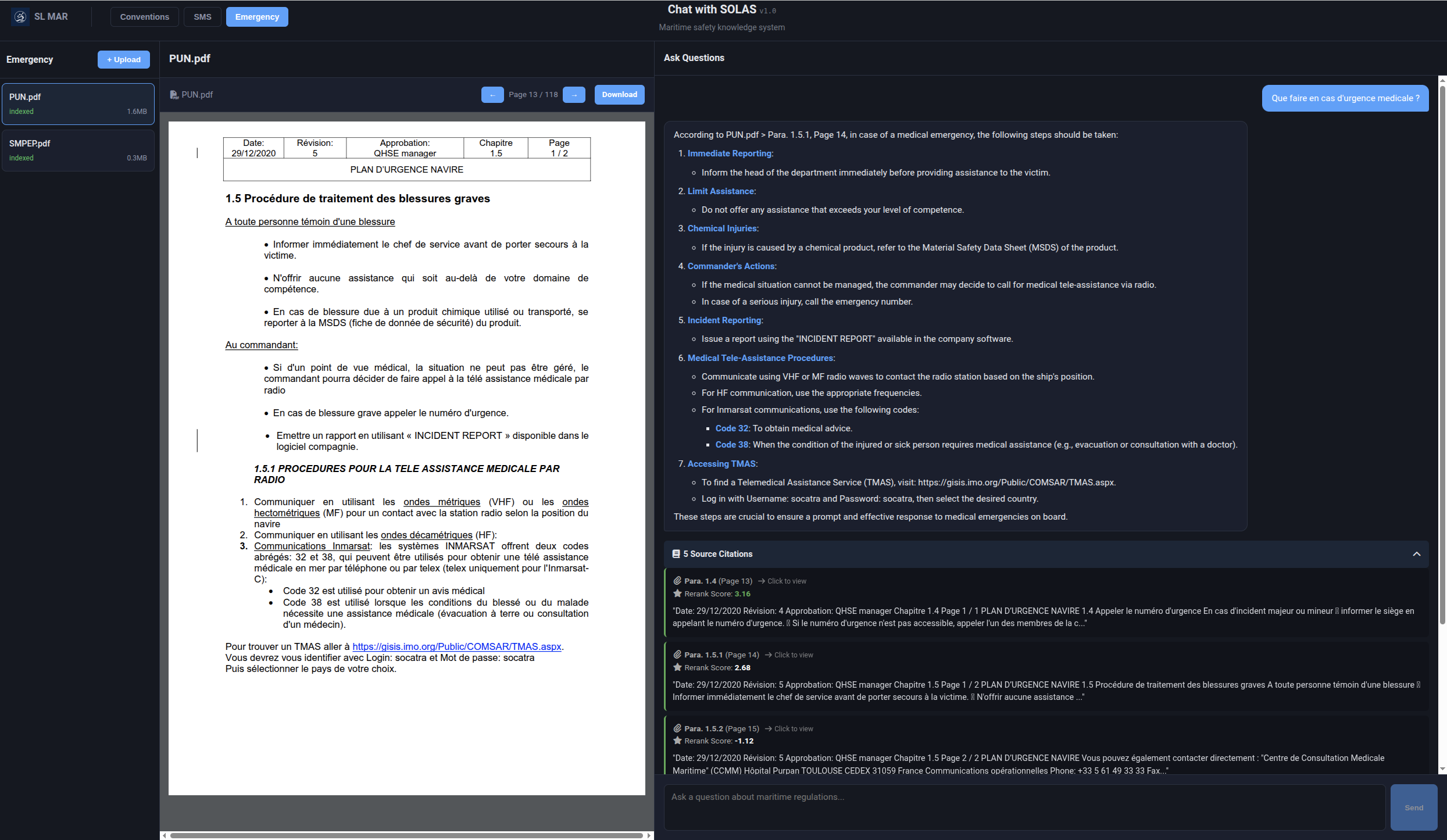
5. Emergency Response
- Challenge: Finding critical information quickly during emergencies
- Solution: Emergency tab with quick access to SMPEP and fire plans
- Example: "Oil spill response procedure for machinery space"
Development Roadmap
Completed ✅
- Hybrid search with semantic + BM25
- Cross-encoder reranking
- Interactive PDF viewer with citation navigation
- Category filtering (Conventions/SMS/Emergency)
- Smart chunking with hierarchy detection
- Tab-specific message histories
- Markdown formatting for answers
- Document upload with FormData handling
In Progress 🔄
- Multi-convention support (expand beyond SOLAS)
- PDF page number correction (re-indexing pipeline)
- Advanced query expansion
Planned 📅
- Visual Content Support: Docling integration for plans and diagrams
- Multi-language: French, Spanish maritime regulations
- Comparative Analysis: Compare requirements across conventions
- Export Features: PDF reports with citations
- User Management: Multi-user support with role-based access
- Audit Trail: Track all queries and answers for compliance
- Custom Collections: Company-specific document collections
- AI Visual Layer: Integration of agentic SMS workflows (future)
Have a feature idea? Submit it via GitHub Issues or contact us directly.